引言
Client/Server 架构下 Server 端的线程模型有着非常重要的作用,它的结构直接决定了服务器可以并发处理的请求数、处理速率、吞吐量等,我们常用的 HTTP 服务框架如 Gin、SpringMVC、Flask等,RPC 通信框架 Dubbo、Thrift 等也都需要考虑线程模型的设计。虽然我们在日常工作中已经很少需要接触这部分的代码,但它的技术思想还是比较精辟的。本文探讨一下常见的三种线程模型:阻塞 I/O & 单线程模型、阻塞 I/O & 多线程模型、I/O 多路复用 & 多线程模型。
阻塞 I/O & 单线程模型
最简单的阻塞I/O(Blocking I/O) & 单线程模型实现,那么服务端将只有一个线程,该线程既用于建立与客户端的 TCP 连接,又用于后续的业务逻辑处理,且新到来的客户端连接请求将被阻塞直至前面的请求处理完成。可以发现,如果客户端的连接数较多且客户端请求的业务逻辑比较复杂,很容易因为处理不及时而在服务端堆积大量的 I/O 请求,造成其它客户端长时间得不到服务。这种现象发生的根本原因在于服务端的单线程模型无法充分利用 CPU 资源,进而无法解决 I/O 与 CPU 速度的不匹配问题。水平扩展服务器数量可在一定程度上提高性能,但仍无法从根本解决问题,因为这种解决方式的实质是增加进程数量,而未对进程内部的线程模型进行改造,如果将单线程模型 改造为多线程模型将大大提升性能。
阻塞 I/O & 多线程模型
该模型将上述的单线程模型改进为了多线程模型,使得服务器端可以同时响应多个客户端的 I/O 请求,客户端连接与服务端线程数之比为 1:1,即每当一个客户端连接建立就创建一个线程,并由该线程负责读取、写入、处理该客户端的数据。可以看出,该模型通过建立子线程,使主线程负责客户端的连接建立,子线程负责异步方式处理读写与处理任务,并发度相较单线程模型有明显提高, 可以支持更多的客户端连接。但该模型存在两个缺陷:
- 如果客户端连接数增多,那么在服务端创建的线程数也将同比增多,内存资源的消耗量较大,容易造成服务器内存溢出
- I/O 操作仍然是阻塞的,每个线程执行到读取与写入操作时会进入阻塞状态,并进行用户空间与内核空间之间的数据拷贝,直至完成后才解除线程的阻塞,阻塞 I/O 导致线程在阻塞期间未能充分得到利用,造成线程利用率降低。
I/O 多路复用 & 多线程模型
I/O 多路复用 (I/O Multiplexing) 允许一个线程可通过记录 I/O 流的状态来管理多个 I/O 流,即一个线程可监视多个文件描述符,当文件描述符进入读或写就绪状态时,内核函数将立即返回准备就绪的文件描述符,此时用户进程再调用 read/write 操作即可将完成数据在用户空间与内核空间的交换。目前 Linux 中实现 I/O 多路复用的内核函数主要是 select 与 epoll,select 函数监视的文件描述符分为 writefds、readfds 和 exceptfds,被调用后会阻塞直至有描述符就绪(可读、可写、异常或超时),当 select 函数返回后,可以通过扫描 fdset 搜索就绪的描述符,select 函数的缺点有三个:
- 单个线程可监视的文件描述符数量有限,Linux 系统一般为 1024
- 遍历 fdset 获取就绪描述符时采用的是线性扫描,即轮询方式,此种方式的缺点是 CPU 时间片浪费较多
- 需要维护一个存放大量 fd 的数据结构 fdset, 在用户空间与内核空间传递开销较大。Linux2.6 内核中的 epoll 函数弥补了 select 函数的不足,该函数首先利用 mmap()将文件映射进内存,加速与内核空间的消息传递,减少了拷贝开销,然后基于事件的就绪通知方式,将用户关系的文件描述符的事件存放到内核的一个事件表中,通过 epoll_ctl 注册 fd,一旦该 fd 就绪,内核将采用 callback 回调机制激活该 fd,epoll_wait 便可收到通知。epoll 引入红 黑树存储描述符,保证调用 epoll_ctl 时插入与删除的时间复杂度维持在 O(logN)
Reactor 模式
Reactor 模式是将 I/O 多路复用技术运用于实践的主流解决方案,Netty 就是基于该模式的。Reactor 模式基于事件驱动机制,将连接建立 ACCEPT、数据读取 READ、数据写入 WRITE 等事件的处理过程相互解耦,通过复用线程的方式提升处理的并发度,同时达到了节省内存资源的目的。其架构如下图所示:
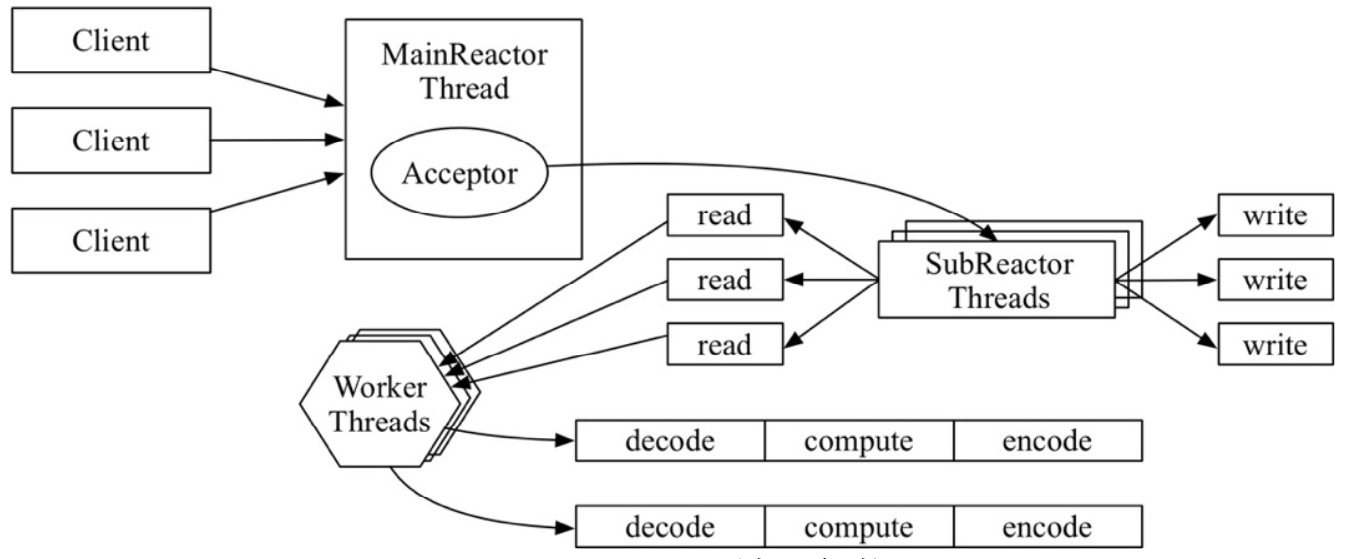
当客户端向服务端发起一个连接请求时,MainReactor 线程中的 Selector 将监听到的 ACCEPT 事件,并将该事件派发给 Acceptor 处理器进行处理,Acceptor 处理器通过 accept() 得到与这个客户端对应的连接,然后将其传递给 SubReactor 线程池,由线程池所分配的 SubReactor 线程注册在 SocketChannel 上所关注的 READ/WRITE 事件,其中每个 SubReactor 均有自己的 Selector 与事件分发的循环逻辑:当监听到 READ 就绪事件时,SubReactor 线程首先通过 read()读取数据,再将数据放入 Worker 线程池完成实际的业务逻辑处理,处理完成后发出 WRITE 就绪事件,之前的 SubReactor 线程将监听到该事件,并调用 write()完成实际的写回客户端任务。可以看出,MainReactor 线程负责的是连接建立任务 accept/connect,而 SubReactor 线程负责的是读写任务 read/write,Worker 线程负 责的是非 I/O 相关的业务逻辑处理任务,设计方案利用单一职责的思想,不仅达到了请求与处理的解耦,还避免了因为数据量过大而导致新来的客户端连接得不到及时处理,因为业务逻辑处理任务过慢导致 I/O 阻塞等情况的发生。
性能对比
本文架设了一个 Thrift RPC 服务端,通过实现不同的线程模型进行测试与对比:针对网络 I/O 方面对比阻塞 I/O 与 I/O 多路复用对响应时间的影响,针对线程方面对比单线程、即时创建线程与线程池对响应时间的影响,并构建4组相互对照的测试方案:阻塞 I/O & 单线程、阻塞 I/O & 即时创建线程、阻塞 I/O & 线程池、 I/O 多路复用 & 线程池。 利用压测工具 JMeter 顺次模拟 5、50、500 和 5000 个并发请求(即等价于相应数量的并发连接),每组让 JMeter 线程组循环执行 5 次后,统计出平均响应时间。
 通过横向与纵向地分析统计图中的数据,下面是对这四种线程模型的评价:
通过横向与纵向地分析统计图中的数据,下面是对这四种线程模型的评价:
- 阻塞 I/O & 单线程:在连接数较少时,能够在调用方可接受的响应时间范围内完成服务,但随着连接数增多,响应时间很容易超出正常范围,其原因是单线程模型仅能同时处理一个请求,而后续到来的请求均需排队等候,直至第一个请求发出处理完成的信号量通知,这个等待过程表现在调用方客户端的线程上是同步阻塞的,若超过最大等待时间将会抛出超时异常;
- 阻塞 I/O & 即时创建线程:通过将单线程模型进化为多线程模型,解决了连接数增多时的性能瓶颈,因此在连接数为 50 时平均响应时间仍能维持在正常范围,但当连接数逐步上升至 500 和 5000 后,响应时间又超出了正常范围,此时线程的频繁创建与销毁成为了性能瓶颈,因为操作系统内核在创建线程的过程中涉及内存分配、拷贝线程结构至内存、列入调度等多项操作,而在销毁线程的过程中涉及等待终止、资源分离、内存释放等多项操作,可见线程销毁具有一定的 CPU 开销,而线程创建的 CPU 开销与内存开销均较大,如果对所创建的线程数量不加约束,服务器很容易因为堆栈溢出而发生宕机。
- 阻塞 I/O & 线程池:在服务启动时预先创建一个含有大量线程的线程池,当请求到达后从线程池中随机选取一个空闲线程为其服务,服务完成后将线程标记为空闲并放回池中,等待被线程池调度给下一个请求,可见该方案通过线程池机制节约了运行时创建与销毁线程的开销,并且可以统一管理线程状态和调度线程。因此该方案在连接数为 500 时仍能保证较短的平均响应时间,但与 I/O 多路复用 & 线程池方案仍有一定差距,原因是阻塞 I/O 的线程模型在发起 I/O 后会阻塞线程直至 I/O 完成,在此期间如果其它线程也均为阻塞态,新到来的请求将无法得到服务,可见线程模型成为了本方案的性能瓶颈。
- I/O 多路复用& 线程池:在主线程中利用内核函数 select/epoll 监视 I/O 的就绪,一旦 I/O 就绪即将 I/O 任务交由 I/O 线程池处理,完成后再交由业务线程池完成具体的业务处理,在全过程中 I/O 线程池与业务线程池中的线程不被阻塞,而是由通知的方式触发任务的执行,任务完成后又立即放回线程池等待下一次的任务通知。可见本方案通过监视 I/O 就绪与线程池配合的方式,最大限度地利用了多核 CPU 资源,使得线程在原本因等待 I/O 完成而发生阻塞的时间段内可以服务其它请求。