引言
遗传算法是由美国的 Holland 教授于 1975 年在他的专著《自然界和人工系统的适应性》中首先提出的,它是一类借鉴生物界自然选择和自然遗传机制的随机搜索算法。遗传算法模拟自然选择和自然遗传过程中发生的繁殖、交叉和基因突变现象,在每次迭代中都保留一组候选解,并按某种指标从解群中选取较优的个体,利用遗传算子( 选择、交叉和变异) 对这些个体进行组合,产生新一代的候选解群,重复此过程,直到满足某种收敛指标为止。其工作流程可以概括成下图:
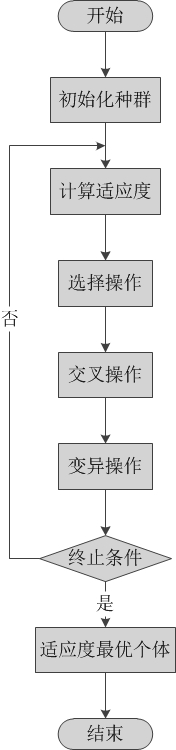
需要指出的是,适应度函数、选择、交叉和变异操作均要根据实际问题进行灵活变更,并非固定模式。本文下面针对TSP这个特定问题,给出实际采用的方案。
实现思路
本文采用面向对象思想实现,分别创建了如下的若干类:
- GeneticAlgorithm:遗传算法类,工作流程环节对应的若干操作均由该类实现
- SpeciesNode:物种结点类,含有基因序列、路径长度、适应度等参数
- List<SpeciesNode>:种群链表类,链接物种构成种群的类
- Constant:常量类,存储地图数据、种群上限数、进化代数、交叉概率、变异概率等参数
初始化种群
不管这个遗传算法有多少道工序,每道工序多么复杂,总得有个开始点吧。那么第一道工序,就是要初始化一波各式各样、不同类型物种(表现在程序上就是基因序列即城市序列不同)构成的种群。所以我们先创建一个种群类:
class SpeciesNode
{
int[] genes;//基因序列
float distance;//路程
float fitness;//适应度
float rate;//轮赌概率
//构造函数
......
//生成初始基因
void createGenes()
{
//初始化基因为1-CITY_NUM序列
for(int i = 0;i < genes.length;i++)
genes[i]=i+1;
//获取随机种子
Random rand=new Random();
for(int j=0;j<genes.length;j++)
{
int num= j + rand.nextInt(genes.length-j);
//交换
int tmp;
tmp=genes[num];
genes[num]=genes[j];
genes[j]=tmp;
}
}
//计算适应度
void calFitness()
{
......
}
}
前面提过,基因序列genes对应着城市序列,即相当于有了一条巡回路线。上面的createGenes()函数采用随机策略初始化出了一段基因序列,但事实上不止这一种初始化策略,还有一种使用较多的是“贪婪策略”,它可以在初始化的时候就快速地锁定在一波路线都较短的种群,其算法流程如下:
Step1 随机初始化一个起始城市\({n_i}\),追加至genes
Step2 若genes已满,转Step4;反之,选出从\({n_i}\)出发到其它所有城市中路线最短的城市\({n_j}\)
Step3 将\({n_j}\)追加至genes,作为新的\({n_i}\),转Step2
Step4 生成genes,结束
具体落实到代码实现上,我们可以使用一个类型为HashMap<Integer>的禁忌表记录已经加入genes的城市,以便在筛选最短城市的时候,可以用它的contains方法先快速判断下该城市是否已加入genes,从而不再参与下一步路线长度的谁小的比较运算,一定程度上缓解了遍历genes的低效。具体代码这里就不贴出来啦。
这种策略看似提升了效率,但却也往往容易陷入局部最优解,因为有时一个当前看起来较次的解,很有可能在经过几轮选择、交叉、变异后超越之前保留的那些局部最优解,究其原因我目前也是很困惑,或许这就是随机算法的魅力吧,或者可以说是大自然进化的神奇。
既然有了genes,那就立马可以算出这条路线的长度distance了,进而我们又可以通过distance算出该物种的适应度fitness。下面我们就来看看这个适应度函数是怎么把distance映射成fitness的。
计算适应度
适应由适应度函数产生,是描述个体性能好坏的主要指标,根据适应度的大小对个体进行优胜劣汰。适应度函数的选择对算法收敛性、收敛速度的影响很大,针对不同的问题需要根据经验来确定相应的参数。下面我们就讨论下TSP问题中常采用的适应度函数:
假设现在有物种:\[s = {n_1},{n_2}, \cdots ,{n_n},{n_1}\]我们很容易求出它的基因序列所表达的巡回路线长度:\[d(s) = \sum\limits_{j = 1}^n {d({n_j},{n_{j + 1}})} \]因为我们更希望路线长度较短的物种生存下来(当然目前路线长度较长的也并不意味着他的后代物种长度也长),而如果直接拿\(d(s)\)作为适应度岂不是南辕北辙了吗?所以我们采用“取倒数”的方法来处理,得到适应度函数:\[f(s) = \frac{1}{{d(s)}}\]下面是SpeciesNode类中计算适应度的函数calFitness的代码实现:
//计算物种适应度
void calFitness()
{
float totalDis=0.0f;
for(int i = 0;i < Constant.CITY_NUM;i++)
{
int curCity=this.genes[i]-1;
int nextCity=this.genes[(i+1) % Constant.CITY_NUM]-1;
totalDis += Constant.disMap[curCity][nextCity];
}
this.distance=totalDis;
this.fitness=1.0f/totalDis;
}
结语
为物种评出了它的适应度后,接下来等待着我们的就是GeneticAlgorithm类中选择算子、交叉算子和变异算子的实现啦,会在下一章一一给出详尽阐述,敬请期待。